AI add-ons incorporating retrieval-augmented generation are everywhere in academic search. But how—and how well—do they work? Our reviewer put Primo Research Assistant, Web of Science Research Assistant, and Scopus AI to the test.
Over the last two years, academic search tools have increasingly incorporated retrieval-augmented generation (RAG) with large language models (LLMs) like GPT (Lewis et al., 2021). These tools—including Elicit, Scite Assistant, and Undermind—retrieve relevant documents from their respective indexes (title and abstract only) and generate summarized answers with citations.
This review will appear in two parts. In this installment, I will focus on these tools’ retrieval functionality. In the second part, to be published at a later date, I will address additional features that identify seminal papers and experts, generate visualizations, and more.
Product Overview/Description
Primo Discovery Service (Ex Libris/Clarivate) is a primary search interface for many academic libraries; it indexes a broad range of content. (Ex Libris also offers Summon, a similar discovery service, and in March 2025 launched an AI tool called Summon Research Assistant. Though Summon Research Assistant looks functionally very similar to Primo Research Assistant, this review will focus only on the latter.) Scopus (Elsevier) and Web of Science (Clarivate) are leading bibliographic citation indexes focused mainly on scholarly articles.
Primo Research Assistant, Web of Science Research Assistant, and Scopus AI all produce direct answers to queries using retrieval augmented generation (RAG): first they retrieve the relevant documents, and then they summarize them with a large language model (LLM). (Please see Katina’s explainer, “A Librarian’s Guide to AI in Academic Search Tools,” for background information about these and other relevant AI technologies.)
While RAG has many variations, these tools take the same fundamental approach. Each tool accepts and even encourages natural language queries (not just keywords) and processes them to retrieve and generate answers. But how do they retrieve and rank relevant items using natural language input?
(Table 1, appearing at the end of this review, provides a comparative summary of the key features and conclusions detailed in the sections that follow.)
Retrieval and Generation Mechanics
Primo Research Assistant passes the user’s query to an LLM, prompting it to generate ten keyword-based variants. These variants, along with the original query, are combined using OR connectors. For example, a query like “impact of climate change on biodiversity” might produce:
(impact of climate change on biodiversity) OR (climate change effects on ecosystems) OR (biodiversity loss due to climate change) OR (climate change and species extinction) OR (environmental changes and biodiversity) OR (effects of climate change on ecosystems and species diversity) OR (how climate change impacts wildlife and biodiversity) OR (climate change consequences for biological diversity) OR (relationship between climate change and loss of biodiversity) OR (impact of global warming on flora and fauna diversity) OR (impact of climate change on biodiversity)
This Boolean search runs against Primo’s Central Discovery Index (CDI), excluding certain content like new items, aggregator content, or records with insufficient metadata. Some content providers, including Elsevier and American Psychological Association, have also opted out (Ex Libris, 2024). The top 30 results are reranked using vector embeddings, and the top 5 are fed to an LLM to generate the final answer.
A notable quirk: items cited in the answer may not always be accessible to the user’s institution because the whole CDI is being searched without taking into account the institution’s holdings.
Web of Science Research Assistant follows a similar retrieval approach, converting natural language queries into Boolean searches via an LLM. But its strategy differs. For the same query (“impact of climate change on biodiversity”), it might produce:
(climate change OR global warming OR climate variation OR climatic changes OR climate variability OR climate crisis OR climate emergency OR greenhouse gases OR anthropogenic climate change OR carbon emissions) AND (biodiversity OR species diversity OR ecosystem diversity OR biological diversity OR ecological diversity) AND (impact OR effect OR influence OR consequence)
This “search block” method breaks the query into key concepts, uses OR to combine synonyms within each block, and connects blocks with AND—a technique familiar to librarians.
Web of Science Research Assistant searches are limited to the user’s entitled Core Collection content. The top eight results, ranked by Web of Science’s default relevance algorithm, are used to generate the answer without additional reranking.
FIGURE 1
Scopus AI also transforms natural language queries into Boolean searches, employing a strategy similar to Web of Science Research Assistant.
But first, a “copilot” interprets the query and decides whether to use a vector search—which converts both queries and documents into embeddings and then matches them via similarity measures—keyword search, or both. It optimizes complex queries by breaking them into parts and tailoring them for the chosen search method—e.g., adding Boolean operators for keyword searches.
FIGURE 2
We also know that Scopus AI employs a specific RAG variant called RAG Fusion (Rackauckas, 2024), which:
Uses an LLM to generate multiple related queries from the input.
Runs these multiple queries (typically via vector embeddings).
Unlike the other two tools, Scopus AI offers both a “summary” (up to ten references) and an “expanded summary” (up to 30 references), with the latter being both broader and more in-depth, likely a benefit of Raw Fusion. Notably, Scopus AI search is restricted to Scopus-indexed papers from 2003 onward, though other features (e.g., finding foundational papers) aren’t subject to this limit.
All three tools accept non-English queries. Primo Research Assistant and WoS Research Assistant respond in the input language; Scopus AI responds only in English.
Prefiltering and Query Parsing
Primo Research Assistant offers prefilters for resource type (Books, Journal Articles, Peer-reviewed) and date (Last 12 months, Last 5 years, Last 10 years, Custom). Users can also apply filters via natural language, e.g., “Give me peer-reviewed articles about large language models from 2020–2024.”
Web of Science Research Assistant excels at parsing metadata filters from natural language queries, recognizing fields like title, DOI, PubMedID, institution, country, citation count, author, journal, volume, recency and more. Examples include:
“Summarize the ideas in DOI: 10.1126/science.1228026”
“Give some papers on cell biology from Germany ”
“Papers published on cell biology at Stanford”
“Search for papers with 20 citations or more on global warming published in Science volume 51, 658”
“What are the most cited/recent papers on microfluidics?”
“Are there any foundational papers on the history of art?” (Clarivate, 2025)
Scopus AI lacks detailed prefiltering options compared to the others but compensates with its hybrid search and copilot optimization.
Output Flexibility While the output of Primo Research Assistant or Scopus AI is always a RAG-generated summary, Web of Science Research Assistant adapts its output based on the query and may offer visualizations (e.g., topic maps, affiliation trends), seminal paper searches, or top author lists. These features will be discussed in more detail in the second installment of this review.
User Experience
Each of these tools is accessed separately from the main search function and none is set as default.
Primo Research Assistant operates through a simple interface—a single search bar, optional post-query filters—accessed via the main menu or a floating widget. On the results page, the top five sources are displayed in boxes above the RAG. A link runs the underlying Boolean search through Primo’s standard search tool answer (the top five may differ due to reranking/eligibility of content). Up to 200 past searches are tracked in a collapsible panel.
FIGURE 3
Scopus AI has a similarly simple interface to Primo’s. Clicking on a reference opens a side panel with details. Summaries occasionally include basic tables but lack the advanced create-table synthesis capabilities seen in Elicit, SciSpace, and Scite Assistant. Integration with the rest of Scopus is limited (no saved AI search history/alerts, limited export options that exclude AI-generated content).
The Web of Science Research Assistant interface is more complex, with a main search bar plus three guided task options (“Understand a Topic,” “Literature Review,” “Find a Journal”). The system adaptively responds to queries, sometimes triggering a guided task instead of a direct RAG answer, which can be confusing. For example, if you enter a concept like “probabilistic models in information retrieval,” it might decide to activate another guided task and show you seminal papers!
FIGURE 4
Contracting and Pricing Provisions
Primo Research Assistant is currently included with institutional Primo VE subscriptions (effectively “free” for end users at subscribing institutions, but not a standalone free product). It lacks COUNTER stats but tracks internal usage analytics, like number of searches and feedback on answer generated (Ex Libris, 2024).
Scopus AI and Web of Science Research Assistant are sold as add-on subscriptions to their respective platforms. Pricing is not publicly available. Neither currently offers COUNTER statistics.
The three tools have similar privacy policies. The Primo Research Assistant and Web of Science Research Assistant policies state that inputs are used only for the current session and not stored or repurposed. Clarivate explicitly notes that Web of Science Research Assistant user data isn’t used to train LLMs, directly or indirectly (Clarivate, 2024). Similarly, Scopus AI assures that queries are neither stored nor used to enhance ChatGPT (Elsevier, 2024c).
Authentication Models
Access to Primo Research Assistant, Web of Science Research Assistant, and Scopus AI mirrors their parent platforms (Primo, Web of Science, and Scopus). All support standard authentication methods, including IP filtering, SSO, and Shibboleth.
Critical Evaluation
Interpretability and Reproducibility of Searches
Primo Research Assistant, Scopus AI, and Web of Science Research Assistant all support natural language queries, but their different approaches impact the interpretability and reproducibility of the search and results.
Web of Science Research Assistant offers high interpretability. It displays the generated Boolean query, and the search results are consistent with the standard Web of Science relevance ranking. Users can understand and validate the retrieval process. Reproducibility is medium; around one in five times, the LLM generates slightly different Boolean strategies on subsequent identical queries.
Primo Research Assistant offers medium interpretability. The initial Boolean generation is somewhat transparent, but the subsequent embedding-based reranking step makes the rest of the process opaque. Reproducibility is medium—similar to Web of Science Research Assistant, LLM variability affects the search around one time out of five.
Scopus AI has low interpretability. While a Boolean query is constructed and shown, the hybrid approach, involving vector search as well as keyword search, makes it hard to understand why specific results are returned. Reproducibility is also very low; the combination of LLM variability and randomness in vector search methods (due to methods like approximate nearest neighbor) leads to inconsistent results more frequently—about half the time.
Reproducibility is a challenge across all three tools. Repeat testing with the same query shows that non-determinism is worse for Scopus AI than for Primo Research Assistant or Web of Science Research Assistant. Boolean Search Strategy Generation The three tools employ different Boolean strategies. For example, for the input, “use of large language models in information retrieval,” the query constructed by each tool’s LLM was as follows:
Web of Science Research Assistant: (large language models OR llms OR generative models OR transformer models OR gpt OR bert OR t5 OR neural networks) AND (information retrieval OR data retrieval OR search engines OR search systems OR information extraction)
This is a “block search” strategy: the LLM splits the query into key concepts (e.g., “large language models” AND “information retrieval”), combines synonyms with OR within blocks, and links blocks with AND—mirroring librarian techniques.
Scopus AI: ("large language models" OR "llm" OR "transformer" OR "neural network") AND ("information retrieval" OR "data retrieval" OR "search" OR "query processing") AND ("natural language processing" OR "nlp" OR "text analysis" OR "semantic search") AND ("machine learning" OR "ml" OR "artificial intelligence" OR "deep learning") AND ("performance" OR "efficiency" OR "accuracy" OR "relevance")
The LLM generates these additional concepts using query expansion; the copilot rewrites the query input before passing it on to create the Boolean search.
Primo Research Assistant: (large language models information retrieval) OR (LLMs in search engines) OR (natural language processing for information retrieval) OR (AI models for document retrieval) OR (transformer models in information search) OR (application of large language models in search engines) OR (impact of AI language models on information retrieval systems) OR (role of NLP models in enhancing data retrieval) OR (utilization of transformer models for improving search results) OR (advancements in information retrieval through large-scale language models) OR (use of large language models in information retrieval)
By generating ten variant phrases, which it combines with the original query using OR, the Primo RA LLM creates a broader, less structured search.
In general, I find all three tools tend to over-expand queries, with Web of Science Research Assistant appearing the most liberal. A skilled human searcher would likely produce a more precise query. Studies show LLMs underperform expert systematic reviewers in Boolean formulation (Lieberum et al., 2025). However, Primo RA and Scopus AI both apply search refinements (rerankings) that can help to surface the most relevant results: Primo RA reranks the top 30 Boolean results using vector embeddings, while Scopus AI combines Boolean and vector searches, reranking for improved relevance. Web of Science RA relies solely on the Boolean search, applying Web of Science’s relevance ranking without reranking. While this approach leads to high interpretability, anecdotal tests (detailed in the next section) suggest it also leads to lower relevance compared to the other tools. Retrieval Augmented Generation Answer Primo RA, Scopus AI, and Web of Science RA all share the ability to produce direct answers with citations using Retrieval Augmented Generation (RAG). To evaluate their performance, I tested four sample queries:
“Is there an open access citation advantage?" Expected answer: “Depends,” 100+ relevant papers (retrieval challenge—Easy).
“Should you use Google Scholar alone for systematic review?” Expected answer: “No,” ~5 to 10 relevant papers (retrieval challenge—Moderate) .
“Empirical papers that use stated preference methods like choice modeling or contingent valuation to estimate researchers’ willingness to pay article processing charges” 1 or 2 relevant papers expected (retrieval challenge—High).
“What were the impacts of casino policies in Singapore by Lawrence Wong?” Trick question; no relevant papers exist. Lawrence Wong, Singapore’s current prime minister (appointed May 2024) entered politics in 2011, years after the 2005 casino decision. This tests “negative rejection” (Chen et al., 2023): Will the tool refuse to answer if no relevant documents are found, or will it hallucinate to try to answer?
Due to the non-deterministic nature of retrieval and generation, I ran each query three times. While RAG answers varied slightly, their overall success or failure remained consistent.
Primo Research Assistant
Query 1: Provided a reasonable answer with relevant citations.
Query 2: Delivered an accurate “No” response with supporting references.
Query 3: Found no relevant results (not good) and correctly stated this in the RAG answer (good).
Query 4: Answered without mentioning Lawrence Wong, focusing on documents detailing general casino policy impacts in Singapore (but not due to Lawrence). It avoided making up the role of Lawerence (good) but also didn’t directly reject the premise of the question.
Scopus AI
Query 1: Performed well, citing relevant papers.
Query 2: Correctly answered “No” with appropriate references.
Query 3: Excelled, identifying the single relevant paper.
Query 4: Failed the trick question. Across three runs, it generated answers citing pre-2010 casino decision papers and mid-2010s studies, none mentioning Lawrence Wong. Uncited claims occasionally implied his involvement as Prime Minister, showing issues with hallucinations.
FIGURE 5
Web of Science Research Assistant
Query 1: Handled well, citing relevant papers.
Query 2: Glitched, showing no results despite relevant papers existing (likely a retrieval error).
Query 3: Struggled, retrieving one semi-relevant paper but producing an irrelevant answer.
Query 4: Did not find any relevant papers and failed to generate any answer.
FIGURE 6
All three tools succeeded in “easy” scenarios (e.g., Query 1) where abundant relevant documents exist. Performance diverged with niche (Query 3) or trick queries (Query 4). Primo Research Assistant proved reliable for straightforward queries and cautious with negatives (Query 3), but it sidestepped the trick (Query 4). Scopus AI performed strongly across most queries, especially niche ones, but faltered on the trick question with a minor hallucination. Web of Science Research Assistant was the best of the three at rejecting the trick query but underperformed overall due to retrieval issues (e.g., Query 2 glitch, weak Query 3 relevance). Of course, this is a very small sample size of test questions; more testing needs to be done.
Recommendation
As noted above, this review focuses on the core RAG capabilities of Primo Research Assistant, Scopus AI, and Web of Science Research Assistant—their ability to generate direct answers with citations based on retrieved documents—while a later installment will evaluate additional features (topic analysis, expert finding, journal finding tools) and the user experience. Accordingly, the basis of my recommendation is the RAG performance observed in the limited testing described above.
Overall Performance
While an early review by HKUST (HKUST, n.d.) ranked Scopus AI below Scite Assistant, Elicit, and Consensus, noting frequent mismatches between cited sources and generated statements, improvements since last year have likely addressed those concerns. In my tests, Scopus AI demonstrated strong RAG performance across straightforward and niche queries, successfully identifying highly specific papers, though it faltered on the trick question designed to test negative rejection. Its use of hybrid search (Boolean + vector) and RAG Fusion appears beneficial for relevance in complex cases but contributes to lower interpretability and reproducibility.
Primo Research Assistant performed reliably for queries with abundant relevant literature and correctly identified when no relevant documents were found for a niche query. It handled the trick question cautiously, avoiding hallucination but also not explicitly rejecting the false premise. Its reranking step adds complexity, offering medium interpretability.
Web of Science Research Assistant showed strength in correctly rejecting the trick question, refusing to generate an answer when no relevant documents supported the premise. But its RAG performance was inconsistent in testing, struggling with retrieval accuracy on some queries (including a glitch showing no results and finding irrelevant results for a niche query). While its direct Boolean search approach offers high interpretability and leverages the high-quality Core Collection, without the reranking or hybrid methods used by the others, its RAG answer relevance seemed comparatively lower.
Scope vs. Quality
Primo Research Assistant draws from the broad Central Discovery Index (CDI), which offers the potential advantage of the inclusion of interdisciplinary and non-journal content, but which is subject to content opt-outs and matching on poor quality or even potentially predatory journal content (similar to other AI academic search tools like Elicit and Undermind). Scopus AI and Web of Science RA use more curated, article-centric indexes (Scopus from 2003+, WoS Core Collection), potentially offering higher average source quality but a narrower scope—a tradeoff that directly impacts the documents available for the RAG process. Users familiar with Scopus or Web of Science may prefer that the AI assistants built into these platforms leverage well-known, high-quality citation indexes compared to newer tools, which often use less familiar corpora (like Semantic Scholar Corpus).
None of the tools use any full text (not even open access full text, unlike some competitors), nor can you mitigate that lack by uploading PDFs of papers, as you can (as permitted by licenses) with Scite, Elicit, or SciSpace. The absence of full text limits the type of question you can ask.
Though of the three, Scopus AI appears to be the best at retrieving relevant items, it is not competitive with “Deep Research” products that do agentic or iterative search, trading off longer processing time for improved retrieval results and long form generation (like OpenAI’s Deep Search, or on the academic front, Undermind or Elicit’s Research Reports.)
The Bottom Line
Librarians evaluating these tools based primarily on their RAG function should consider which approach best aligns with their users’ primary needs: broad discovery (Primo Research Assistant), potentially higher relevance in complex searches despite opacity (Scopus AI), or high interpretability and reliable negative rejection at the potential cost of retrieval consistency (Web of Science Research Assistant). A full evaluation should also incorporate the findings on additional features that I will present in the second installment of this review.
Of the three, Scopus Ai is probably the most mature and can be useful if approached with care by expert researchers. But further testing, particularly with institution-specific scenarios, remains crucial. And while evaluating the technical performance of such tools is crucial, it’s also important to consider the broader implications of integrating them into the research and learning workflow.
Feature
Primo Research Assistant (launched September 2024)
Scopus AI (launched January 2024)
Web of Science Research Assistant (launched September 2024)
Index Used
Central Discovery Index (CDI) with exceptions (e.g. news content, aggregator collections, and selected content owner opt-outs) (Ex Libris, 2024)
Scopus index since 2003. Metadata and abstracts (articles, books, reviews, chapters, proceedings, etc.) (Elsevier, 2024b)
Web of Science Core Collection (user entitled holdings)
Content Used for RAG
CDI metadata and abstracts. No full text.
Scopus metadata and abstracts (from 2003 onward for summary generation). No full text.
Web of Science metadata and abstracts. No full text.
Retrieval Process
LLM generates 10 keyword variants to add to original query (ORed). Top 30 relevant results reranked via vector embedding(Ex Libris, 2024).
Cormack, G. V., Clarke, C. L., & Buettcher, S. (2009). Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 758–759. https://doi.org/10.1145/1571941.1572114
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (No. arXiv:2005.11401). arXiv. https://doi.org/10.48550/arXiv.2005.11401
Lieberum, J.-L., Töws, M., Metzendorf, M.-I., Heilmeyer, F., Siemens, W., Haverkamp, C., Böhringer, D., Meerpohl, J. J., & Eisele-Metzger, A. (2025). Large language models for conducting systematic reviews: On the rise, but not yet ready for use—a scoping review. Journal of Clinical Epidemiology,181, 111746. https://doi.org/10.1016/j.jclinepi.2025.111746
Rackauckas, Z. (2024). RAG-Fusion: A New Take on Retrieval-Augmented Generation. International Journal on Natural Language Computing,13(1), 37–47. https://doi.org/10.5121/ijnlc.2024.13103
10.1146/katina-052025-2
Aaron Tay is the head of data services at Singapore Management University and a highly experienced librarian with over 15 years in the profession. He has wide-ranging interests spanning areas like discovery systems, open access, bibliometrics, and analytics. Aaron is known for exploring new areas of librarianship and sharing his insights through his blog, “Musings about Librarianship,” and presentations. His inquisitive nature drives him to constantly experiment with new ideas to advance library services.
Thank you for your interest in republishing! Anyone is free to use and reuse the article text and illustrations created by Katina for non-commercial purposes under a CC BY-NC license. Please see our full guidelines for more information. Photographs and illustrations are not included in this license. This HTML is pre-formatted to credit both the author and Katina.
This is a required field
Please enter a valid email address
Approval was a Success
Invalid data
An Error Occurred
Approval was partially successful, following selected items could not be processed due to error
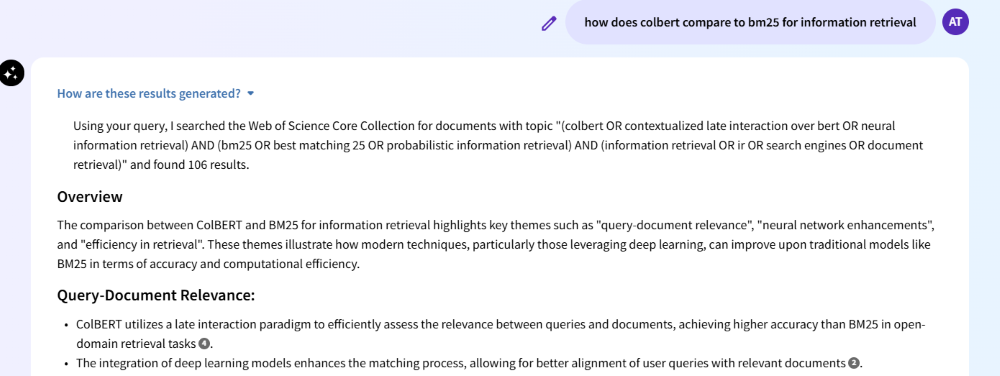 FIGURE 1
FIGURE 1 FIGURE 2
FIGURE 2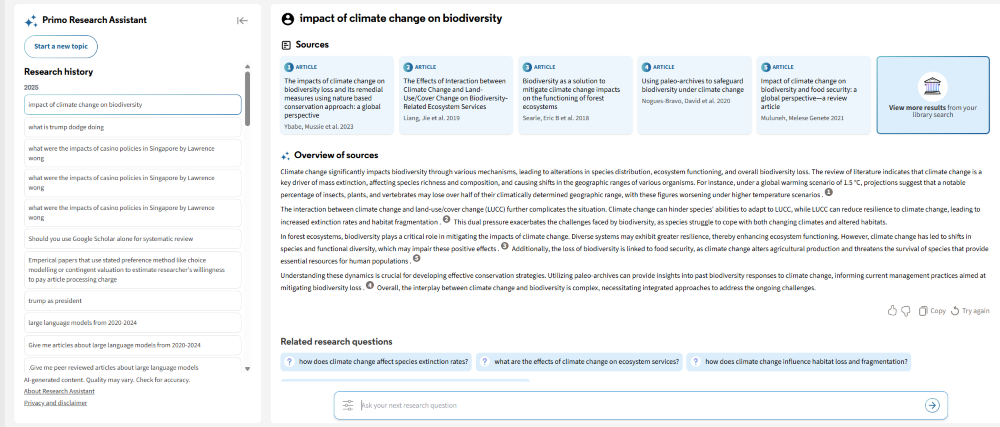 FIGURE 3
FIGURE 3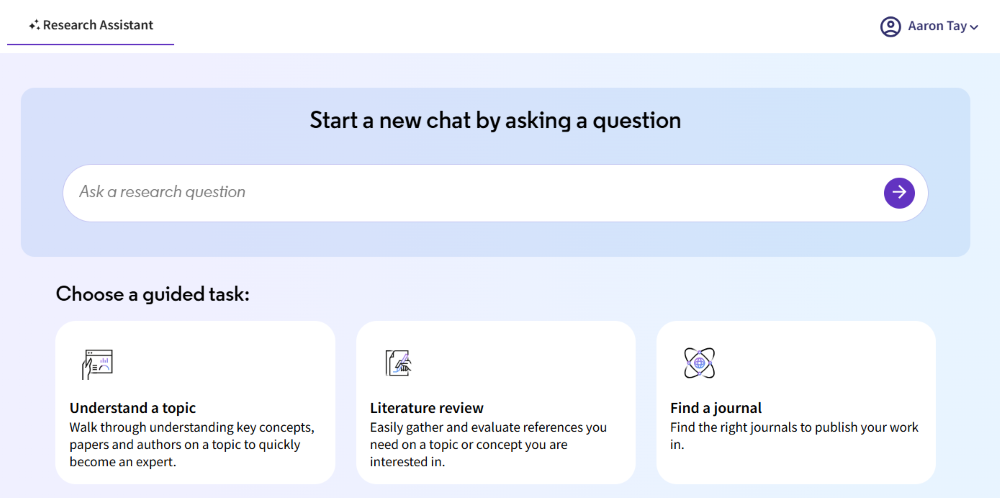 FIGURE 4
FIGURE 4 FIGURE 5
FIGURE 5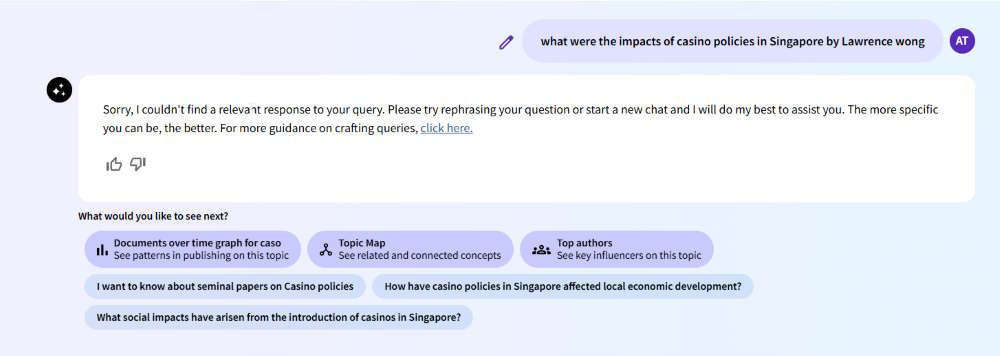 FIGURE 6
FIGURE 6