New AI Tool Shows the Power of Successive Search
Undermind.ai is a state-of-the-art AI search tool with the potential to delight researchers. But with official benchmarks lacking, potential subscribers should thoroughly test individual use cases.

Undermind.ai is a state-of-the-art AI search tool with the potential to delight researchers. But with official benchmarks lacking, potential subscribers should thoroughly test individual use cases.
Undermind.ai is a next-generation AI search tool that uses state-of-the-art AI-powered algorithms. Like other generative AI-enhanced search systems, including Elicit.com and SciSpace, it employs a blend of lexical or keyword search and embedding-based vector or semantic search. However, it distinguishes itself by claiming higher precision and more comprehensive search results due to its unique algorithms designed to mimic human discovery processes. These algorithms adapt based on previously found relevant content to perform successive keyword, semantic, and citation searches, meaning each search takes 2-3 minutes to complete. Undermind also summarizes papers found using generative AI, similar to Scite.ai assistant and Elicit. Like many AI search tools, it utilizes the Semantic Scholar corpus (title and abstract only).
Undermind.ai targets the academic user and focuses heavily on improving the quality of search results. Like many modern search tools, it employs a blend of lexical or keyword search and embedding-based vector or semantic search (which leverages the latest AI advances using neural nets based on the transformer architecture to allow matching of queries to documents by contextual meaning even if there is no keyword match). But it goes beyond that by using a search algorithm designed to imitate a human’s discovery process. This means that, like a human searcher, once it has found relevant content, it adapts to conduct successive keyword and citation searches. Additionally, it directly employs large language models like GPT-4 to classify papers into three levels of relevancy (later versions of Undermind may use GPT-4 for a select number of papers, when necessary, based on relevance scores). This process is computationally expensive, taking up to 3 minutes to complete.
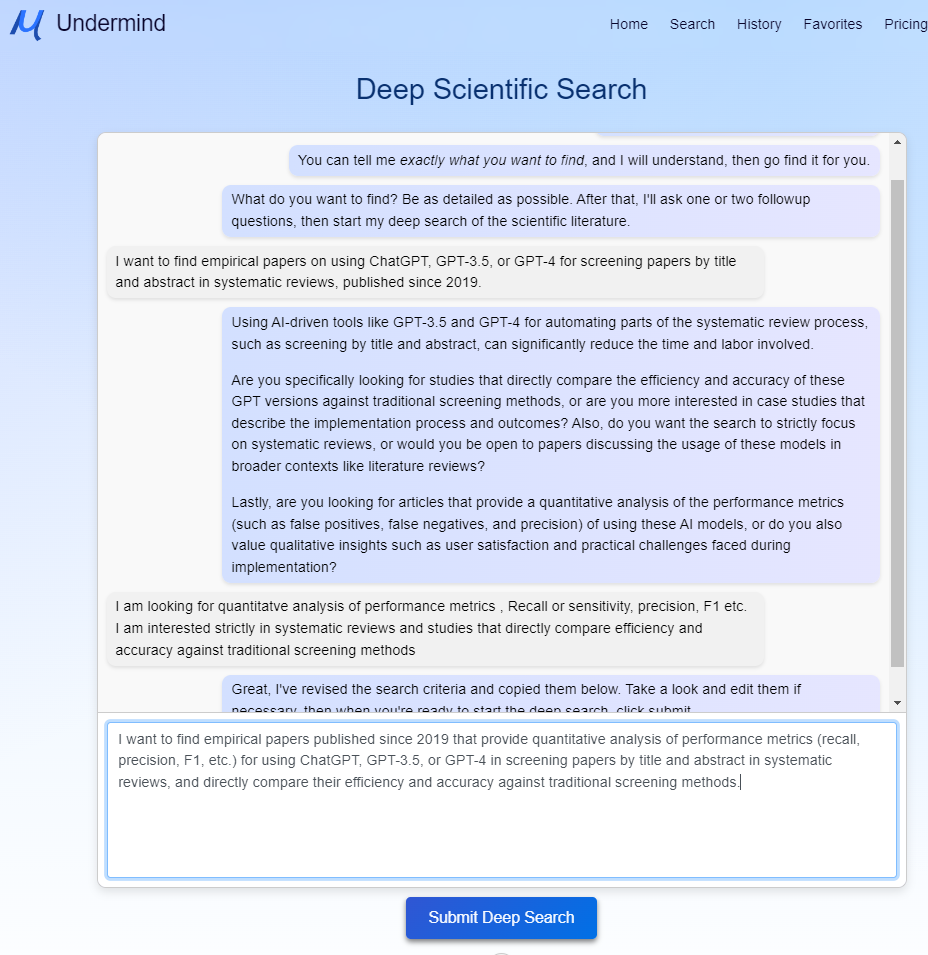
Users are encouraged to enter detailed queries, as if explaining them to a colleague. A chatbot prompts users for more details to refine and clarify the search query. This feels akin to the reference interview and probing that librarians do (see Figure 1).
Once the search query is ready, Undermind conducts a comprehensive search of the abstracts and titles on Semantic Scholar that can take 2-3 minutes.
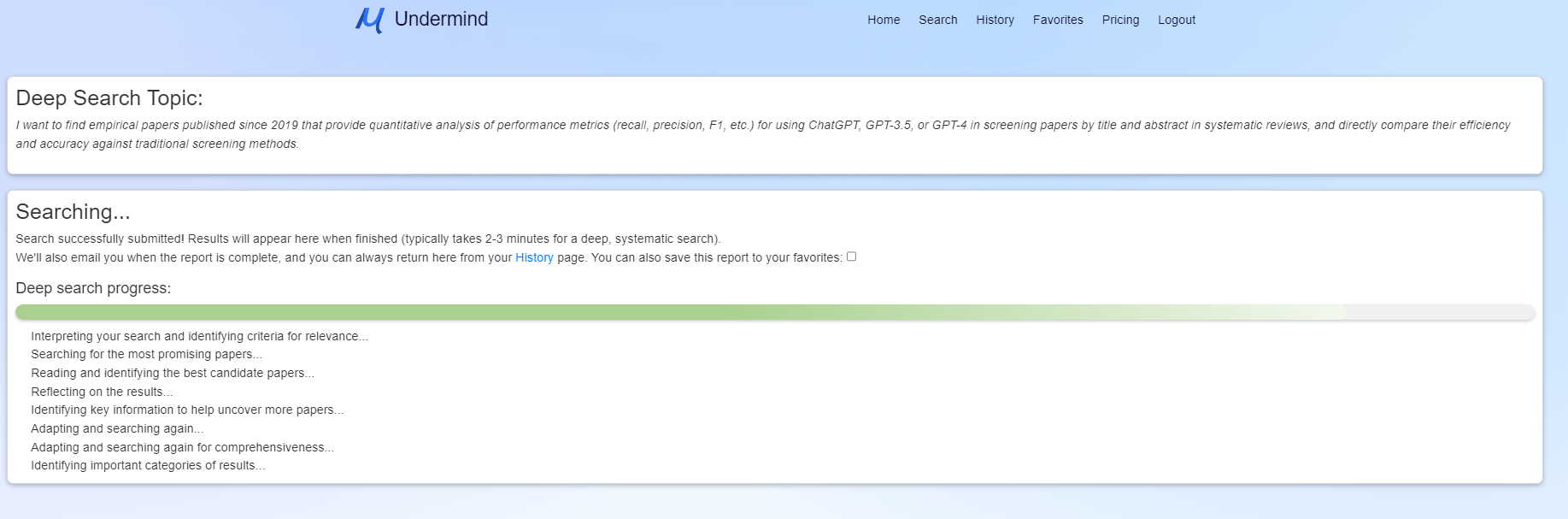
As shown in Figure 2 above, Undermind conducts not just a single search, but several iterative searches based on previous results.
The default results page, shown in Figure 3, includes a summary generated by a large language model and three subsections the user can expand to view.
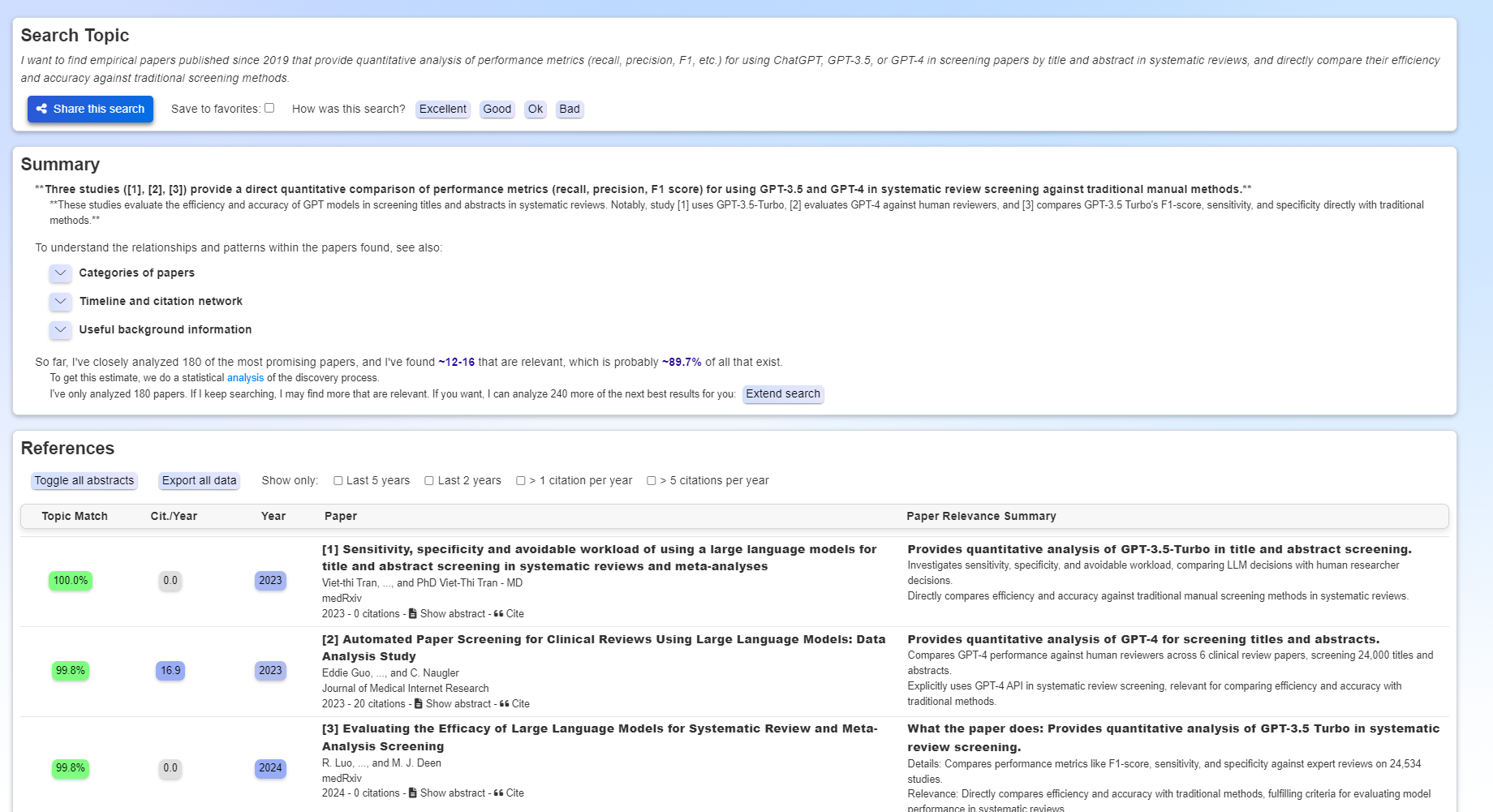
A unique feature of Undermind is its statistical model that estimates the total number of relevant papers on a topic. The model, or “The discovery curve,” is based on the idea that when users start to exhaust the relevant papers in an index, they will start getting fewer and fewer relevant papers. This feature can offer users confidence that they aren't missing highly relevant content.
In the example query in Figure 3, Undermind analyzed 180 papers and estimated it found 12-16 relevant papers, projecting this to be approximately 89.7% of all relevant papers. A user could extend the search beyond the initial 180 papers, though in this particular case, with an estimated 90% already found, that additional search would likely yield diminishing returns.
The reference section at the bottom of the page lists all 180 papers, ordered by topic match percentage, with AI-generated descriptions of their relevance.
The “Categories of papers” section classifies papers into categories that can be used to filter the reference list, while the “Useful background information” section explains how Undermind makes these classifications (see Figure 4).

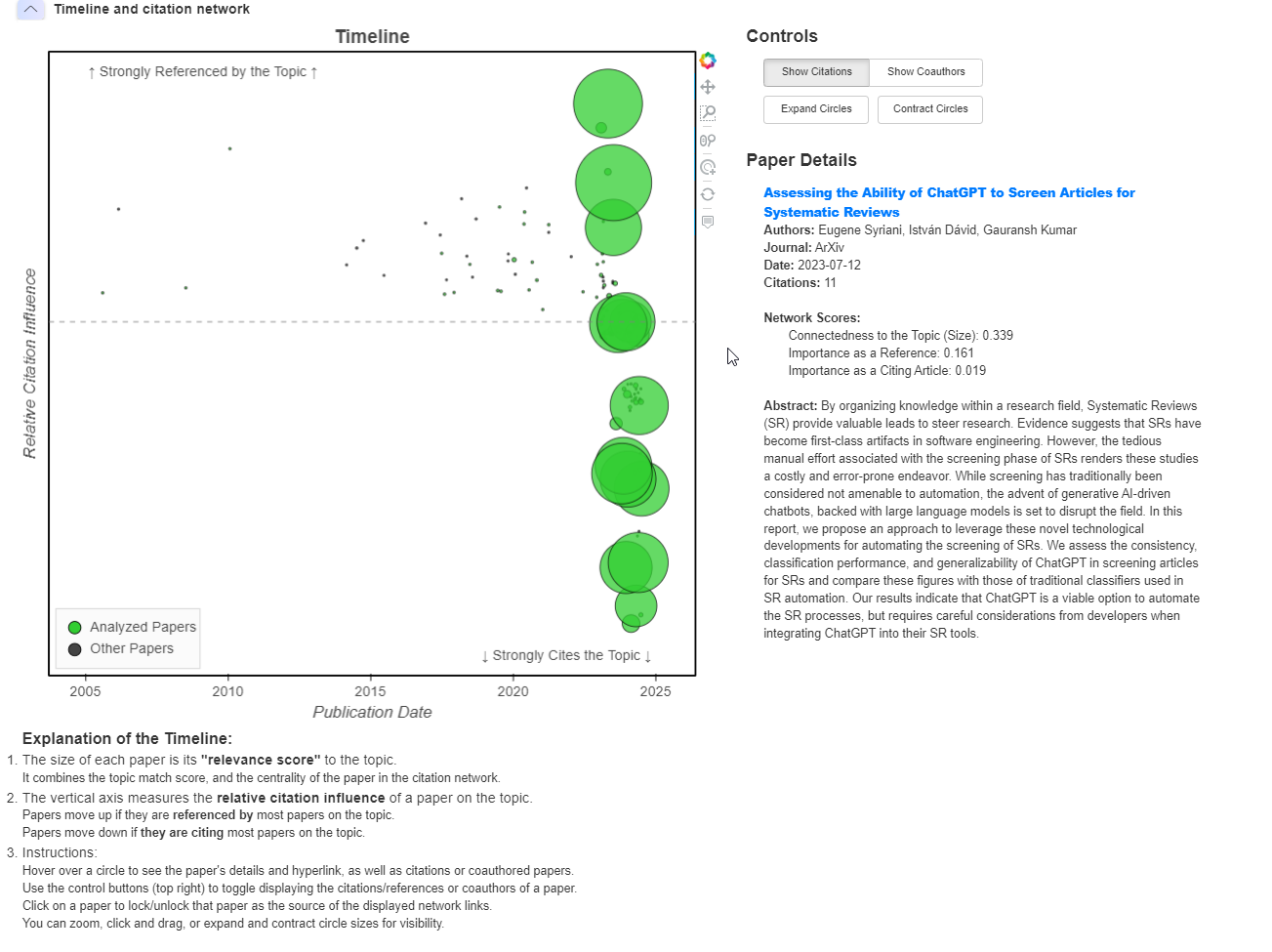
The timeline and citation network section (see Figure 5) displays a graphical representation of all analyzed or found papers. The horizontal axis is a timeline, while the vertical axis measures the “relative citation influence” of each paper, with papers that are referenced most within the network appearing at the top and papers that most often cite others appearing at the bottom. Node size reflects a combination of the topic match score and citation network centrality.
Undermind’s web interface is intuitive. The ability to share search results pages with others (no account needed to access) is particularly helpful, and the reference section allows exporting in CSV/BibTeX/RIS formats. However, usability would be enhanced if the tool allowed sorting in the reference section by displayed columns (like Year, Title, and Citations per year) and provided additional filters (e.g., by journals).
I didn’t find the timeline and citation network function particularly useful, and the controls to zoom in and out are awkward to use. In terms of accessibility, a Voluntary Product Accessibility Template is not available, but when I corresponded with the Co-Founder and CEO, J. Ramette, J. indicated that Undermind strives to meet WCAG (personal communication, July 7, 2024).
The free version of Undermind allows ten searches per month, with each search analyzing only 50 papers instead of the usual 150. Monthly and annual subscription plans are available for individuals and academic institutions, with bulk discounts for organizations available on request.
Organizational pricing is based on seats, with administrators choosing which users have access. For institution-wide access, Undermind employs a concurrent user model, pricing for a capped number of users per month or semester.
For example, at an institution with an annual subscription for 50 seats, 50 user accounts would be able to access the paid version of Undermind.ai and perform unlimited searches every month. The fifty-first person from the institution would still be able to access past search results or reports but new searches would be limited to the permissions of a free account. Access would reset at the beginning of the next month (J. Ramette, personal communication, July 7, 2024).
COUNTER use statistics are not available, and interlibrary loan and MARC records are not applicable.
In terms of redistribution of data, the terms of use state, “You are allowed to freely share, distribute, and disseminate any search results you create while using the Site with any third parties, including but not limited to non-subscribers, other institutions, and the general public.”
Undermind offers authentication via usernames/passwords, IP filtering, and SSO, including Shibboleth, LDAP, and OpenAthens (J. Ramette, personal communication, July 7, 2024).
The closest competitors to Undermind are Elicit.com, Scite.ai (via Scite Assistant), and SciSpace, all tools that use large language models and generative AI to search and generate multi-document summaries. However, none currently performs successive searches based on earlier findings as Undermind does. As a result, while Elicit and Scite.ai provide faster responses, they may not match Undermind’s precision and recall. Undermind is also distinguished by its unique modeling of the search process that estimates how much more of the topic remains undiscovered. Elicit is reportedly working on a similar feature, referencing an Undermind whitepaper (Smith, 2024).
Academic search tools—from startups like Scite.ai, Elicit, and SciSpace, as well as legacy vendors like Scopus AI—are increasingly integrating Generative AI and large language models. Undermind is currently unique in trading off processing time for higher search quality by mimicking human discovery processes. The question remains whether the search quality is sufficiently improved to be worth the additional processing time.
My initial early testing, using gold standard sets found in systematic reviews, looks promising. Additionally, paid individual subscribers at my institution have offered extremely positive reviews of the search quality compared to conventional search tools. However, there has been no official benchmarking of Undermind against other tools except for a whitepaper released by Undermind.
The whitepaper claims an earlier version of Undermind discovered ten times more relevant articles than the top results in Google Scholar (Hartke, 2024). As this earlier version utilized arXiv (using full-text and not just abstracts), these results cannot be compared to the current version of Undermind, which uses only titles and abstracts from Semantic Scholar, allowing for cross-disciplinary searching capabilities and faster speed but sacrificing the ability to analyze the full text of papers.
Librarians supporting systematic reviews or evidence synthesis might wonder if Undermind can approach, if not match, the sensitivity and precision of rigorous systematic reviews conducted by human experts. If so, Undermind could potentially save months, if not years, of human work. While recent studies show large language models like GPT-4 can achieve high sensitivity and specificity in title and abstract screening (Guo et al., 2024; Tran et al., 2024), Undermind goes beyond screening to also conduct iterative searches, which is more complex.
While there is still no official benchmarking of Undermind’s performance against human screeners, it was never designed for formal systematic review or evidence synthesis. Unlike human screeners, who understand that abstracts do not always contain the full story and may mark articles for further screening at the full-text stage, Undermind might consider them irrelevant (J. Ramette, personal communication, June 28, 2024). I have seen examples of papers being penalized and ranked low for this very reason.
Another important issue for some librarians is the non-transparency of Undermind’s search process. Beyond a few general statements about what the system is doing (see Figure 2), the company provides few details. This contrasts with, for example, Scite Assistant, which shows the search strings used.
Nevertheless, rigorous systematic reviews constitute only a small percentage of all literature reviews. In most other cases, compared to current tools, one that can provide significantly more precise results with reasonable recall (particularly for matching highly relevant works on complex topics or concepts) would make the process of literature review more efficient and effective, improving the quality of research.
Using Semantic Scholar as a source isn’t as big a drawback as one might think. Per SearchSmart (searchsmart.org) estimates, Semantic Scholar has about 200 million records, more than twice as many as Scopus, which has roughly 80 million records. In terms of size, it is comparable with sources like Lens.org and OpenAlex, and is clearly dominated only by Google Scholar. However, gaps in coverage might exist for areas in the humanities and non-journal content such as clinical trial records or law cases.
Unlike Scite.ai, which includes citation contexts of selected papers (through open access or publisher agreements), or Elicit, which indexes the full text of open access papers, Undermind currently uses titles and abstracts only with no full text.
In terms of individual pricing, at USD 16 per researcher, it compares favorably with a ChatGPT Plus subscription, though it is a more focused tool.
Undermind is a new, state-of-the-art AI search tool that has the potential to delight researchers with the quality of its results. It is designed and optimized to find articles that are highly relevant to a complex topic or concept via an iterative, human-like process that is especially effective at surfacing content that uses different key words or language from the searcher.
But given the lack of official benchmarks, potential subscribers should thoroughly test individual use cases.
Guo, E., Gupta, M., Deng, J., Park, Y.-J., Paget, M., & Naugler, C. (2024). Automated paper screening for clinical reviews using large language models: Data analysis study. Journal of Medical Internet Research, 26(1), e48996. https://doi.org/10.2196/48996
Hartke, T., Ramette, J., & Ai, U. (2024). Benchmarking the Undermind Search Assistant. https://www.undermind.ai/static/Undermind_whitepaper.pdf
Smith, P. (2024). From grep to SPLADE: a journey through semantic search. (2024, June 13). The Elicit Blog. https://blog.elicit.com/semantic-search/
Tran, V.-T., Gartlehner, G., Yaacoub, S., Boutron, I., Schwingshackl, L., Stadelmaier, J., Sommer, I., Alebouyeh, F., Afach, S., Meerpohl, J., & Ravaud, P. (2024). Sensitivity and specificity of using gpt-3. 5 turbo models for title and abstract screening in systematic reviews and meta-analyses. Annals of Internal Medicine, 177(6), 791–799. https://doi.org/10.7326/M23-3389
10.1146/katina-100924-1
Copyright © 2025 by the author(s).
This work is licensed under a Creative Commons Attribution Noncommerical 4.0 International License, which permits use, distribution, and reproduction in any medium for noncommercial purposes, provided the original author and source are credited. See credit lines of images or other third-party material in this article for license information.