Stocking the Librarian’s Publishing Integrity Toolkit
The number of tools available to help library staff identify potential research misconduct is rapidly expanding. Here are some recommendations.

The number of tools available to help library staff identify potential research misconduct is rapidly expanding. Here are some recommendations.
Note: this is the third of a three-part series about how libraries can respond to publishing integrity problems in the context of open access agreement management. Part One describes the role libraries could play and discusses strategies for managing OA agreements in light of these problems. Part Two drills down into specific practices through which libraries can identify and respond to publishing integrity problems and explores the significant challenges ahead. Part Three reviews several online tools being developed to assist such efforts.
As described in Part One of this series, the management of open access agreements within academic libraries creates the possibility for library staff to play a new role in the ongoing publishing integrity crisis. When library staff monitor open access agreements for publishing integrity problems, they take on, to some extent, the role of the sleuth. Taking on a new role requires a new set of tools.
Our training and skills prepare us at least somewhat for this work. Consider our ability to evaluate resources, explore publication histories, analyze bibliographies, maintain awareness of technological innovation, and exercise attention to detail. Even so, independent sleuths have been working on these problems for many years, developing strategies for spotting publishing integrity issues that are likely new to a librarian’s regular toolkit.
To begin to bring those strategies to a library audience, this review explores a few simple web-based tools that can help users identify possible misconduct. There are, of course, many other practices that are essential for a robust framework for research integrity and validation (for example, the broad adoption of persistent identifiers such as Open Researcher and Contributor ID (ORCID) for authors and Research Organization Registry (ROR) for institutions), but here we will focus on particular tools available for the individual sleuth in the library.
Many readers will have heard of Retraction Watch Database (RWD) though they may not have found it directly applicable to their work. This is a database of retracted scholarly articles that was launched in 2018 by the well-known blog of the same name and acquired by CrossRef in 2023.
RWD can list all posted retractions for any given journal, institution, publisher, or (if you are mindful of the lack of authority control) author, providing a quick snapshot of the “official” landscape of publisher decisions.
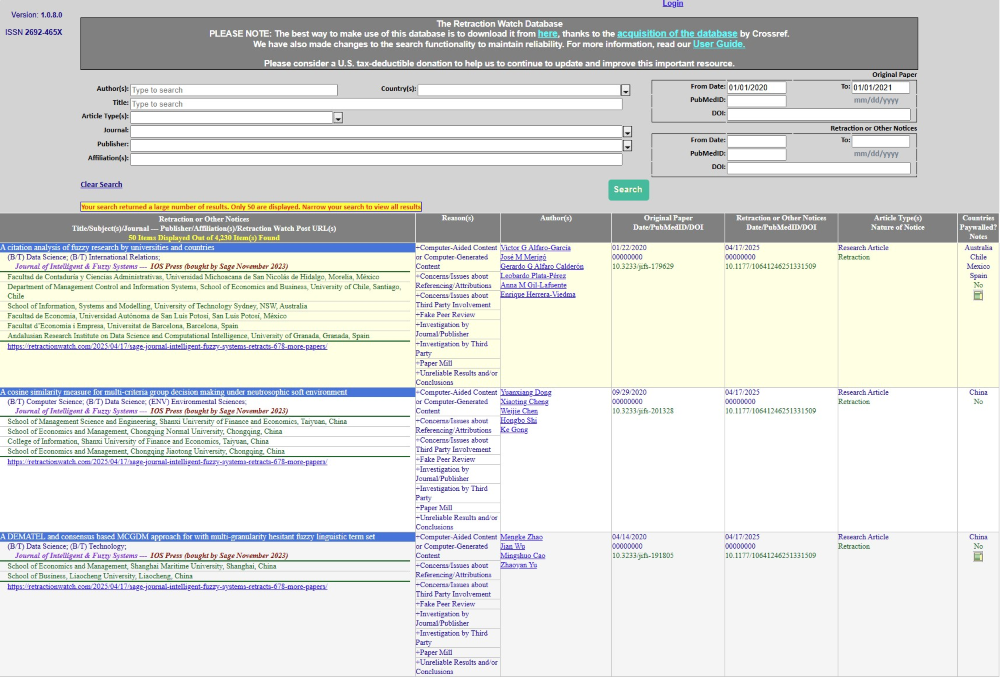
The initial interface is not eye-catching, but it does have a number of useful filters. The date filters are handy for retrieving the newest retractions or understanding the retraction history of a particular publication or publisher. In multiple metadata fields, including the author field, a dropdown list populates as you type with values from the database. If you are exploring a network of authors involved in multiple retractions, the ability to quickly discover whether a person is listed in the database just by inputting a name in the author field can be very useful. The actual search can take a few seconds, so the dropdown is a timesaver when you are analyzing a long list of names.
To compare large quantities of data against the database, though, it is probably best to work from a download of the complete comma-separated value (CSV) file provided by CrossRef.
For smaller investigations, the basic results list on the site can be sufficient.
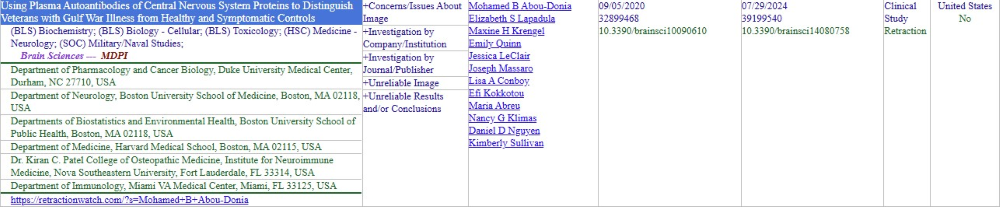
Figure 3 shows an entry for an article in the MDPI journal Brain Sciences. On the left side are the article title, subjects, and journal title/publisher, followed by the authors’ institutional affiliations. One inconvenient point about this orientation is that it is not easy to connect an author’s name (two columns to the right) with an institution visually, even though this affiliation information is important for disambiguating authors. Another word of caution is that clicking on the linked authors’ names in the third column does not return only results for the same person. Rather, if you click “John Smith,” the database will run a new search for every occurrence of “John Smith” and return every John Smith, Alan John Smith, and John Smith Johnson. For rare names, the name links can help a user quickly understand a network of authors, but you still have to be careful to disambiguate whether the results are really the same person. Unfortunately, many of these authors are not using ORCIDs, and it is often necessary to open the article and match the author with the institution to verify the author’s identity.
The second column is a brief summary of the reasons for the retraction, which is helpful at a glance, though it is still worthwhile to read the actual retraction. That is where columns four and five are useful, because they contain the date and DOI for the original paper and the retraction. It would be nice if the DOIs were links instead of just text, but that is a minor issue.
Though not much to look at, RWD is still a good place to do a fast and dirty initial check on a publication, institution, or a group of co-authors.
Signals is a start-up company attempting to create a profitable subscription publishing integrity tool for institutions and publishers. As the name implies, Signals is meant to bring together in one dashboard various publishing integrity indicators for individual articles or across an entire journal. Currently, individual users who sign up for an account can access parts of the platform to search for reports on specific articles for free. Broader, more publisher-oriented features are behind a paywall. While promising, Signals is still new and developing.
The free functionality allows a user to enter a DOI to retrieve information about an article. Figure 5 shows an example from a retracted paper. You can see that Signals may flag an article in a number of ways. It reports how many citations a paper has, its retraction status, and information about self-citation within the article. One particularly helpful feature is that it also flags the authors’ affiliations and notes when the affiliated institution has an unusual retraction rate, which can be a significant red flag. A recently added “expert contributions” feature is promoted as including data from internet sleuths, much like its integration with the Problematic Paper Screener (which we discuss in more detail below).
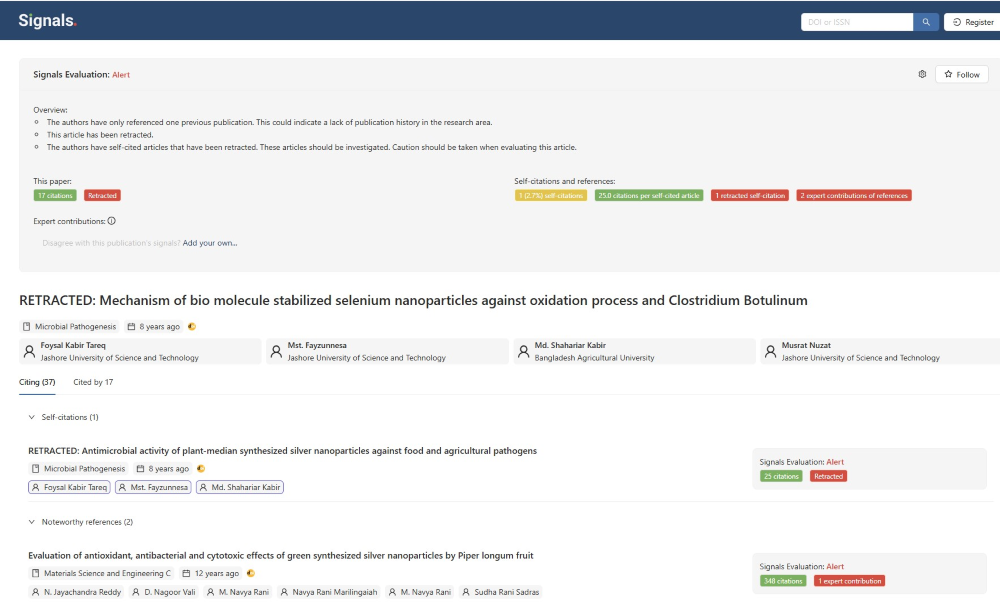
Much of the platform seems geared toward providing tools for publishers to scan article submissions or entire journals, which makes it difficult to predict whether Signals will continue to develop in directions that will be open and useful to the independent publishing integrity sleuth. Currently, the database does not flag authors with a high retraction rate and seems reluctant to strongly flag individual articles that have not already been retracted. It can be handy, though, for quickly looking at self-citations and institutional affiliations.
PubPeer is an online platform for “post-publication peer review.” Unlike many past efforts to solicit user responses to published academic papers, typically in the form of a comment box, PubPeer has cultivated a sizeable and sustainable community of active users. It has set itself apart primarily by allowing anonymous comments but requiring them to be based on publicly verifiable information, thereby creating a forum for readers to openly point out problems without fear of reprisal and for authors to respond to criticisms. PubPeer thus provides an invaluable window into concerns about a paper long before a publisher issues a retraction or expression of concern.
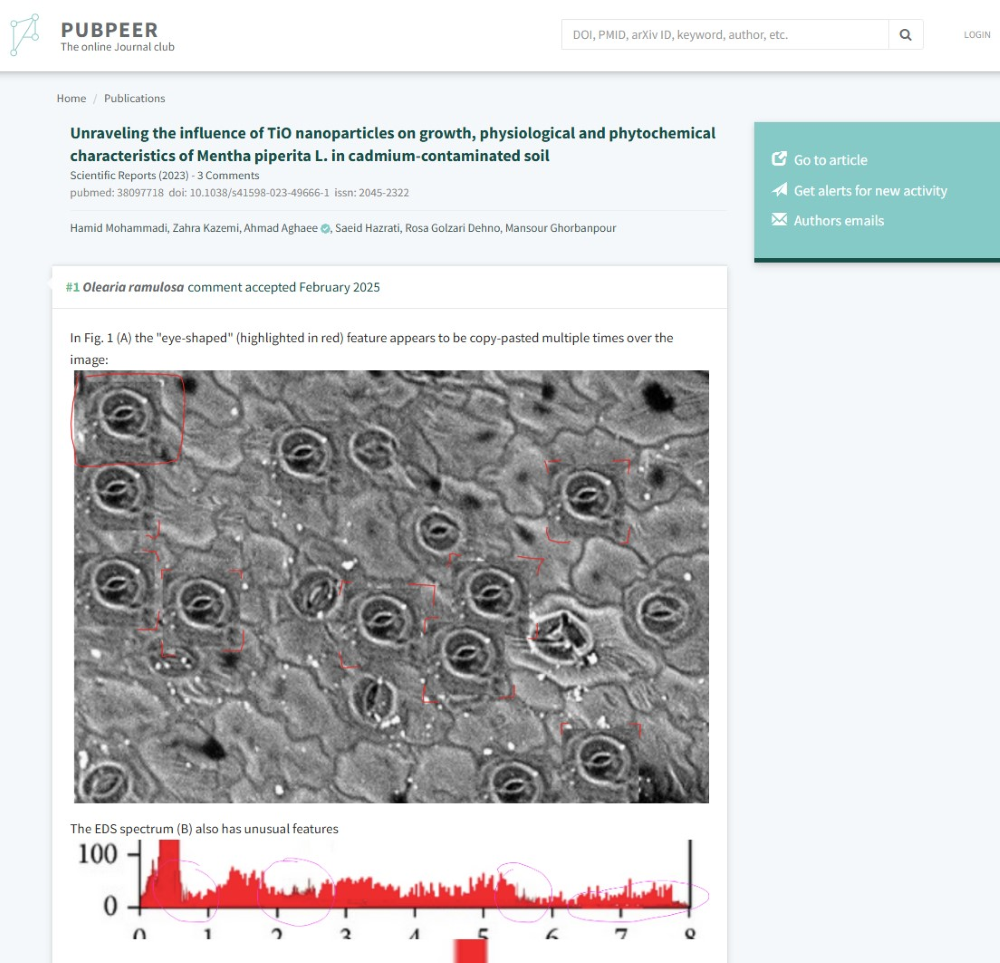
Through the free PubPeer web interface, a user can search by title, author, abstract, or updates. A title or DOI search reveals whether a specific article has received comments, but this will be the case for only a small fraction of all papers. An author search can locate discussions of a particular author’s work, but disambiguation is necessary, as only names are indexed, not ORCIDs. It is also possible to search for specific research topics or methods, to get a sense of whether they have frequently been a subject for sleuth scrutiny.
While this free PubPeer interface has its uses, three additional options more powerfully leverage the valuable conversations on the platform.
For journal editors and publishers seeking to maintain the integrity of their own publications, a fee-based “Journal Dashboard” offers a variety of useful features: alerts for comments on relevant journals, comment tracking and resolution, more advanced search features, the ability to provide “Certified Journal” responses, and more.
A similar dashboard exists for institutions. It is most likely to be of interest to research integrity officers but could appeal to any library with a strong institutional mandate to pursue this work.
For most of us, the best way to use PubPeer is through the free browser extension, which is currently available for Chrome, Safari, Edge, and Firefox. This elegantly simple extension searches PubPeer for all DOIs on any HTML page loaded in the browser (it does not currently work with PDF files). If any have comments, a banner displays linking to them. Readers of journal articles can thereby be alerted, within the flow of their normal processes and without taking any additional steps, of possible red flags not only in a given paper, but in that that paper’s cited references. (A PubPeer plugin for the Zotero reference manager works similarly.)

PubPeer comments on a paper do not necessarily indicate problems with that paper. This is true for a number of reasons. First, PubPeer commenters are fallible. Second, while in practice the vast majority of comments are critical, PubPeer does allow for comments that are positive or neutral. So the great value in the PubPeer browser extension alert is not only that it flags potentially problematic papers, but that it links directly to the relevant discussion, so that readers can judge for themselves.
The Problematic Paper Screener (PPS) is a utility developed by Guillaume Cabanac, a professor and sleuth at the University of Toulouse. It is based on the concept of “fingerprints,” signals in the text of published papers that may indicate problems. The PPS screens papers based on seven fingerprints as well as several other detectors.
Perhaps the most notable fingerprint is “tortured phrases,” defined as “an established scientific concept turned into a nonsensical sequence of paraphrasing words”—for example, “bosom peril” instead of “breast cancer” or “choice timber” instead of “decision tree” (Cabanac, Labbé, & Magazinov; 2022). These appear to be generated by authors using automated paraphrasing software to evade plagiarism detection. Another red flag detected by the utility is “feet of clay,” defined as papers that cite retracted papers.
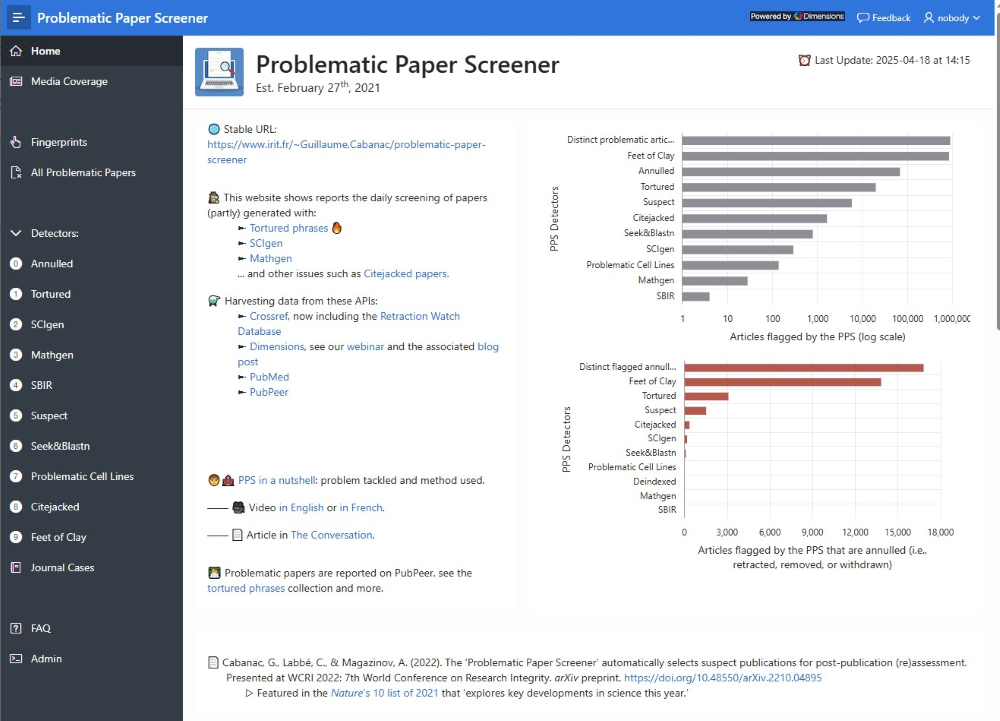
The utility works by applying these detection algorithms to a data feed of all articles indexed by the Dimensions bibliographic index and displaying the findings whenever a fingerprint is identified. This valuable list can be browsed, sorted, and filtered by a variety of metadata values, including year of publication, journal title, publisher, times cited, and the number of problems detected.
This alone would be a powerful contribution. But it is only the first step. After the utility flags an article, humans then verify what the algorithms have identified as potential issues and post their findings on PubPeer. Those PubPeer comments are then linked from the PPS and become prominently visible to anyone reading the article while using the PubPeer browser extension.
Currently, over 25,000 articles flagged by the utility are awaiting human verification—a clear opportunity for volunteers looking to contribute. This list can be sorted by the papers with the most “tips” or fingerprints identified, as well as those receiving the most citations.
By screening nearly the entirety of published scientific output, the PPS offers perhaps the best early warning system for problems with particular publishers and journals, flagging potential issues well before the slow retraction process can be completed. For example, filtering by publisher and year reveals that Elsevier’s annual share of all papers flagged by the PPS has been increasing each year since 2021. Or that the publication with the most flagged papers thus far in 2025 is not a megajournal like PLOS One or Scientific Reports, but Wiley’s International Wound Journal. For libraries with journal agreements up for renewal, a comparison of a publisher’s share of flagged papers with their overall share of the literature might be a worthwhile investigation.
In this article, we have focused on openly available tools we’ve found helpful in past explorations that we believe are noteworthy for a library audience interested in getting started in publishing integrity sleuthing. But the number of tools relevant to publishing integrity investigations is rapidly expanding. Companies like Morressier have come out with publisher-oriented tools, and the STM Integrity Hub has created a walled garden for publisher collaboration. Looking at the wider landscape, some additional resources deserve mention:
Many new commercial tools are leveraging artificial intelligence in an attempt to get a step ahead of the paper mills. Some of the largest publishers have also developed their own in-house tools to better route problem papers to a desk rejection.
In Part One of this series, we argued that open access agreement management provides an appropriate frame for libraries to contribute to broader efforts to ensure the integrity of the scientific record. In Part Two, we described in greater detail what this work might look like and frankly discussed its challenging nature. In this concluding part, we’ve reviewed a number of resources and discussed how they might be applied in an academic library context.
While this discussion has novel aspects, it dovetails with important work that academic libraries have already pursued for many years. Instruction librarians help students (tomorrow’s researchers) understand the ethical and legal implications of their information behavior, encouraging critical thinking about what it takes to do good research and who should get credit for it. Research data repository managers protect the integrity of research data and share it with the world. Institutional repository managers integrate their systems with publisher retractions and expressions of concern. Of course, collection managers are there ensuring that collection funds do not flow toward the publication of low quality or fraudulent research.
In countless ways, libraries have shaped the information landscape—investing time, feedback, and money in the bibliographic databases, persistent identifiers, metadata registries, publishers, and platform providers that together uphold the reliability of scholarly communication. But the pressure being applied to this system requires new adaptations. May it never be said that academic libraries sat back and watched while the scientific record became unworthy of our trust.
Cabanac, G. (2025, April 19). Problematic Paper Screener. https://www.irit.fr/~Guillaume.Cabanac/problematic-paper-screener/
Cabanac, G., Labbé, C., & Magazinov, A. (2022, January 13). “Bosom peril” is not “breast cancer”: How weird computer-generated phrases help researchers find scientific publishing fraud. Bulletin of the Atomic Scientists. https://thebulletin.org/2022/01/bosom-peril-is-not-breast-cancer-how-weird-computer-generated-phrases-help-researchers-find-scientific-publishing-fraud/
The Center for Scientific Integrity. (2018). The Retraction Watch Database. http://retractiondatabase.org/.
Else, H. (2022, September 23). ‘Papermill alarm’ software flags potentially fake papers. Nature. https://www.nature.com/articles/d41586-022-02997-x
The PubPeer Foundation. (2025). PubPeer: The Online Journal Club. https://pubpeer.com/
Research Signals Limited. (2024). Signals. https://research-signals.com/
10.1146/katina-080725-1
Copyright © 2025 by the author(s).
This work is licensed under a Creative Commons Attribution Noncommerical 4.0 International License, which permits use, distribution, and reproduction in any medium for noncommercial purposes, provided the original author and source are credited. See credit lines of images or other third-party material in this article for license information.