While its results are fewer in number and slower to load than Google Scholar, Internet Archive Scholar provides a free, open, transparent, and nonprofit alternative to the popular commercial tool. Most critically, it ensures continued discoverability of and access to sources that have vanished from the open web.
In October, a series of cyberattacks took down many of the services of the Internet Archive (IA), including, for three weeks, delaying the completion of this review, Internet Archive Scholar. The cyberattacks came on the heels of a lawsuit brought by publishers alleging copyright infringement in relation to their controlled digital lending (Hachette Book Group Inc v. Internet Archive). These events marked a period of significant challenge for the nonprofit, which since 1996 has preserved and maintained the accessibility of often-ephemeral web pages and other cultural content.
The IA servers now contain more than 145 Petabytes of data, including billions of web pages and many millions of books and texts, images, and audio and video recordings.
IA Scholar is a search engine that surfaces research articles and other scholarly documents from the Internet Archive, including public web content, digitized content from print and microform materials, and other content from archive.org and its partners.
It serves as a free, open, transparent, and nonprofit alternative for searching scholarly content, offering user-friendly search results that connect the searcher to a non-paywalled live publisher document, repository document, and/or archived copy in the Internet Archive’s Wayback Machine, including sources that have disappeared from the web since their IA capture.
Losing access to so much IA content during the cyberattacks underscored for me the valuable role that IA serves, not only in the general information ecosystem, but in scholarly research.
Product Overview/Description
Internet Archive Scholar indexes over 35 million items spanning the eighteenth century to the present. No particular geographical, community, or language emphasis is intended, though it seems likely that English-language scholarship from developed Western countries is more highly represented, as is a common issue across the scholarly communication landscape. Because the tool is freely and openly available, relies on preserved copies of works, and requires no special software or plugins, it has the potential to benefit any researcher, particularly those seeking resources that have succumbed to “link rot” or whose original hosting website has vanished. Interface simplicity renders the tool accessible to novice researchers, while powerful query support, although less visible on the surface, invites flexibility for power users.
User Experience
The basic search bar defaults to full-text keyword searching, and Internet Archive Scholar does not provide an “Advanced Search” interface to guide users through field-specific searching. But Lucene query syntax is supported to target specific metadata fields: for example, type:article-journal or year:>2020. Double quotation marks indicate exact phrases, as expected.
When I entered the query string journal: “college & research libraries” !journal:“news,” the Lucene syntax teased out results from College & Research Libraries but not College & Research Libraries News (the exclamation point negates a search term, similar to a Boolean NOT).
Users familiar with Boolean queries and wildcard operators common to platforms like EBSCOhost may need some time to acclimate to this syntax, but the tool provides its own concise user’s guide and links to significantly more detailed documentation from the Elasticsearch project (Scholar User Guide, n.d.). A handful of metadata facets are available in an intuitive side menu to filter search results by specific resource type, publication date, and format availability.
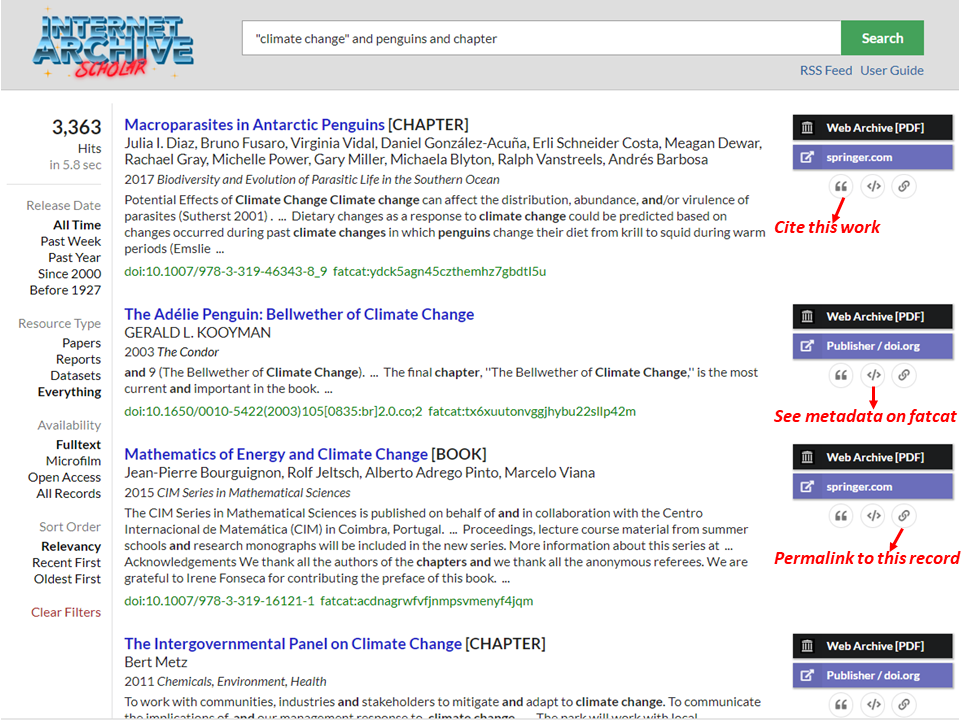
Individual results display in a clear and familiar-feeling way (see Figure 1), with the item title, author(s), year, and journal name identified above a brief excerpt of text relevant to the search terms. In a more novel twist, a variety of persistent identifiers (PIDs) are listed below the content snippet. PIDs include Digital Object Identifiers (DOIs), PubMed ID (PMID), arXiv pre-print server ID, and an article-level identifier for works in the Directory of Open Access Journals (DOAJ), particularly those with no DOI.
Full text may be accessed via a PDF or HTML copy archived in the Internet Archive’s Wayback Machine, so that availability of works captured in the archive is assured regardless of their current “live” hosting status. When journal, conference, and other websites vanish over time, these captured versions are essential for preserving scholarly content; the Internet Archive Scholar interface ensures that this scholarly content remains searchable and discoverable. When available, links are also provided to the publisher’s version of record (when not behind a paywall) and other “live” versions on reliable platforms like PubMed or arXiv.
figure 1
A formatted reference to a work can be copied from its result listing in a selection of styles. A persistent link to the item’s record in Internet Archive Scholar is also available, along with a direct link to the item’s full metadata from Fatcat, the public bibliographic database leveraged by Internet Archive Scholar. Additionally, several tags may appear at the bottom of a result listing to provide additional context when applicable: for example, multiple versions of a work are available, a work is preserved on JSTOR, a work is published in a journal listed in the DOAJ, or a work is published on an established open access platform such as Open Journals System (OJS) or SciELO.
Scholar’s provider, the 501(c)(3) nonprofit library Internet Archive, considers one of its missions to be serving “people who have difficulty interacting with physical books”; they strive for “AA-level WCAG compliance to ensure the accessibility of the site to users on a variety of platforms and devices, including screen readers” (About the Internet Archive, n.d.). That said, much of the website information regarding accessibility focuses on the digitized books in the Internet Archive with significantly less emphasis on the Scholar search engine. I was unable to locate a Voluntary Product Accessibility Template (VPAT) or accessibility roadmap. When I viewed a preserved copy of an article from Scholar results in the Wayback Machine, the frames on the page did not pass a WCAG accessibility check; for a more accessible option, a user can download the PDF.
Contracting and Pricing Provisions
Internet Archive Scholar is free with no paid or premium options, so no contract is required for use. This also means no institutional usage statistics are available. The provider website asserts an intention to make the “the full corpus” available to researchers for “text and data mining purposes,” though some datasets are only available upon request (About Internet Archive Scholar, n.d.). Snapshots of the full metadata corpus from Fatcat are freely accessible online (About Internet Archive Scholar, n.d.).
Authentication Models
NA
Competitive or Related Products
The competitive tool which most immediately springs to mind is Google Scholar. The two search engines clearly have some overlap, but they also have some notable differences. Google Scholar’s corpus is notoriously lacking in transparency, whereas Internet Archive Scholar leverages a public bibliographic database (About Internet Archive Scholar, n.d.).
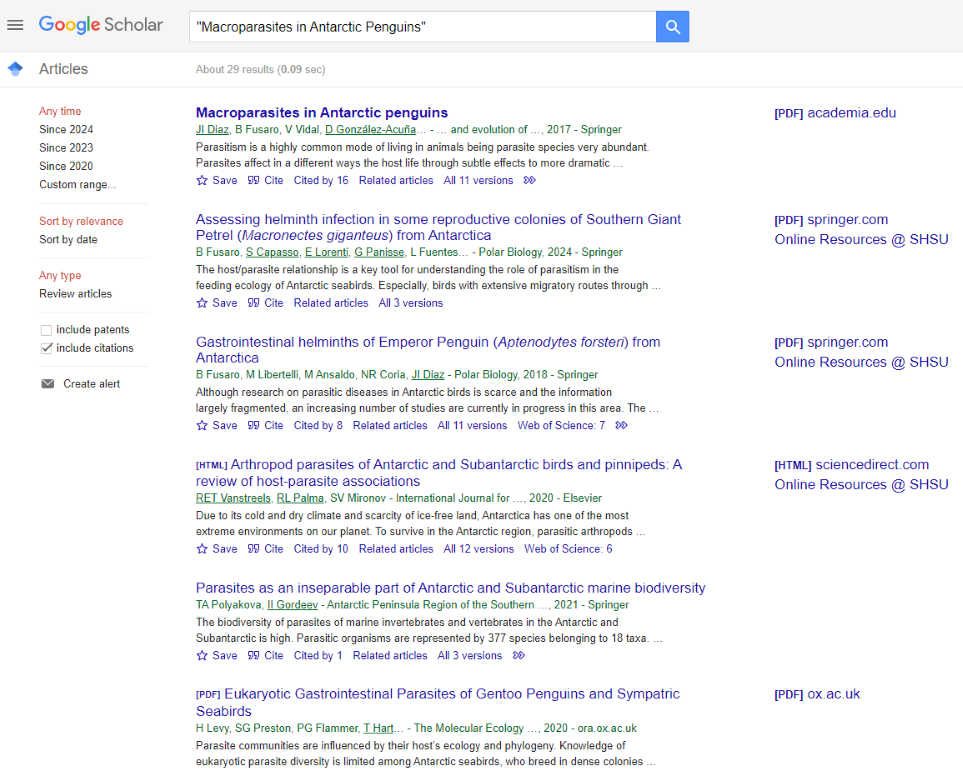
When I searched both tools for the query “climate change” and penguins, Google’s results did appear notably faster and tended to be more recent. Google’s results were also more compact, fitting more items onto a page (see Figure 2). But I found Internet Archive’s results easier to read, since publication information is spaced out more clearly and excerpts are longer, providing more context for matched keywords (see Figure 1).
FIGURE 2
Google’s total number of search results was greater—41,100 versus an initial 6,310 on Internet Archive’s—but by investigating some filters I was able to expand Internet Archive’s default to an actual total of 7,807. As may be familiar, some of the Google Scholar results were simply marked as [Citation] and lacked a URL to locate an abstract or full text. Most of the Internet Archive results were accessible (albeit sometimes as black-and-white scans of microfilm), but when I overrode the default filters to show everything, results labeled [Stub] sometimes appeared with the statement, “We don't yet know of a public preservation copy of this work.” In the case of the Stub illustrated in Figure 3, clicking on the Publisher / doi.org button launched only the Sage Journals homepage without locating the unique work that the DOI should have represented.
FIGURE 3
Interestingly, both tools returned the same article as their first result. Internet Archive’s second result did not appear on Google’s first page of results, while Google’s second result appeared fourth in Internet Archive’s results. Both searches contained conference proceedings as well as journals, including from publishers like Multidisciplinary Digital Publishing Institute (MDPI) with controversial reputations. Internet Archive included at least some online books and chapters from providers like Springer Nature; meanwhile Google also included results from Google Books and ProQuest dissertations. Both tools seemed to find open content from preprint servers and institutional digital repositories. Google also presented results from ResearchGate and Academia.edu, which could be a benefit or a disadvantage, depending on the user’s perspective. Internet Archive provided a filter for datasets, which Google did not.
Overall, the tools provided a similar experience, but Google Scholar produced significantly more, and more recent, results. Meanwhile, Internet Archive Scholar allows researchers to access archived copies of sources that have ceased to be openly available—for example, when a publisher closes, or a conference site is taken offline. Internet Archive Scholar might especially benefit researchers who lack access to robust document delivery services or those wanting alternate ways to search for a resource that lacks full text in Google Scholar.
Critical Evaluation
Internet Archive Scholar presents academic sources in a clear and comfortable interface. While results are fewer in number and slower to load than Google Scholar, it provides a highly functional, more transparent, and free nonprofit alternative to the popular commercial tool and, most critically, it ensures continued discoverability of and access to a myriad of scholarly sources that have vanished from the open web. The lack of an Advanced Search and a reliance on Lucene as opposed to Boolean syntax may pose a stumbling block for some users, but, in general, the straightforward keyword searching and user-friendly display of results will make the tool accessible for most searchers.
Recommendation
I recommend Internet Archive Scholar for any student, faculty member, researcher, or member of the public who needs to access scholarly sources they have discovered from the web, or anyone who is seeking an open, low-barrier way to find academic sources and prefers an addition or alternative to Google Scholar.
Erin Owens has been a member of the faculty of the Newton Gresham Library at Sam Houston State University since 2007, supporting information literacy and information access for students, faculty, and staff through various roles. In her current role as Scholarly Communications librarian, she helps researchers from novice to expert with a wide array of topics pertaining to planning, conducting, disseminating, and evaluating research. As associate director of Library Public Services, she also oversees the work the Circulation and Interlibrary Services units, comprising 9 staff positions and approximately 27 student assistants. She formerly served as both Research & Instruction librarian for History & Foreign Languages and Web Services librarian.
Thank you for your interest in republishing! Anyone is free to use and reuse the article text and illustrations created by Katina for non-commercial purposes under a CC BY-NC license. Please see our full guidelines for more information. Photographs and illustrations are not included in this license. This HTML is pre-formatted to credit both the author and Katina.
This is a required field
Please enter a valid email address
Approval was a Success
Invalid data
An Error Occurred
Approval was partially successful, following selected items could not be processed due to error